[AWS] S3 버킷 생성 CSV파일 업로드
이번 글에서는 S3의 개념과 함께 로컬 db 데이터를 CSV 파일로 변환하여 S3에 업로드하는 과정까지 정리해보았다.
S3란
Amazon S3는 AWS에서 제공하는 객체 스토리지 서비스로,
이미지, 문서, 로그 파일, 백업 등 모든 데이터를 인터넷상에서 안전하게 저장할 수 있다.
✅ S3를 사용하는 이유
1. 무제한에 가까운 저장 용량 (확장성)
- S3는 데이터 용량 제한이 없기 때문에, 수십만 개의 파일도 문제 없이 저장 가능
- 프로젝트가 커져도 따로 서버 증설 없이 그대로 사용 가능
2. 높은 내구성 및 안정성
- S3는 데이터를 여러 위치에 중복 저장해서, 거의 절대적으로 안전하게 보관 가능
- 디스크 고장, 네트워크 문제 등에도 데이터 손실 확률이 매우 낮음
3. 다양한 AWS 서비스와 연동
- Athena, Lambda, Glue, Redshift 등과 바로 연결 가능
→ 빅데이터 분석, 서버리스 아키텍처에 매우 유리
* S3는 클라우드 기반 프로젝트에서 로그, 통계, 사용자 데이터 등 다양한 정보를 저장하는 데 많이 사용된다.
S3는 단순한 저장소를 넘어 다양한 AWS 서비스와 연동해 데이터를 분석하거나 처리할 수 있다는 점에서 매우 유용하다.
S3 버킷 생성하기
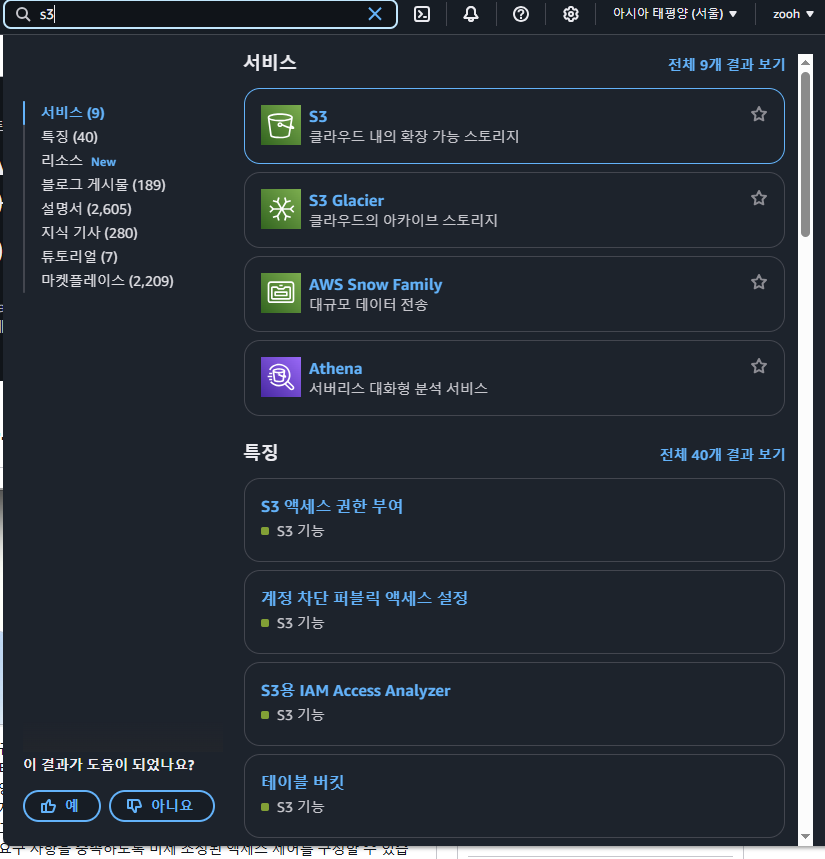
🔹 1. AWS 콘솔 접속
- AWS 콘솔에 로그인
- 상단 검색창에 S3 입력 → 클릭
🔹 2. 버킷 만들기
- [버킷 만들기] 클릭

2.버킷 이름 : 기존 버킷이름과 중복되지 않는 고유한 이름으로 입력
3. 리전 : 빠른 서비스를 위해 '서울'로 세팅

4. 퍼블릭 액세스 차단 설정은 기본값 유지
5. 나머지도 그대로 두고 하단의 [버킷 만들기] 클릭

대시보드를 확인해보면 버킷이 정상적으로 생성되었다.

이제 DBeaver에서 로컬에 저장되어있는 member테이블의 raw 데이터를 csv파일로 변환하여 업로드 해보도록 하겠다.

좌측의 테이블에서 우클릭 > 데이터 '데이터 내보내기' 클릭

'CSV 파일로 내보내기' 클릭

구분자는 콤마로 되어있어야한다.


저장될 디렉터리를 확인 후 'Start' 버튼을 누르면 해당 디렉터리에 CSV파일이 생성된다.

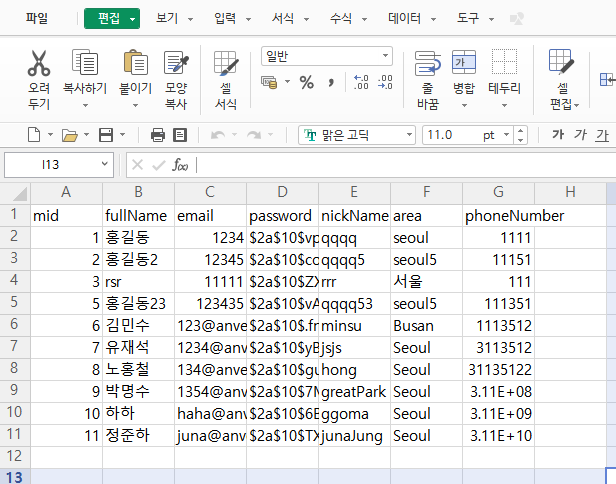
생성된 경로로 들어가 CSV파일을 확인해보면 데이터가 잘 export된 것을 확인 할 수있다.
Exel로 연결하여 파일을 열 경우 한글이 깨져 한셀로 연결 후 CSV 파일을 연 상태이다.
생성한 버켓 내 파일을 업로드한다.
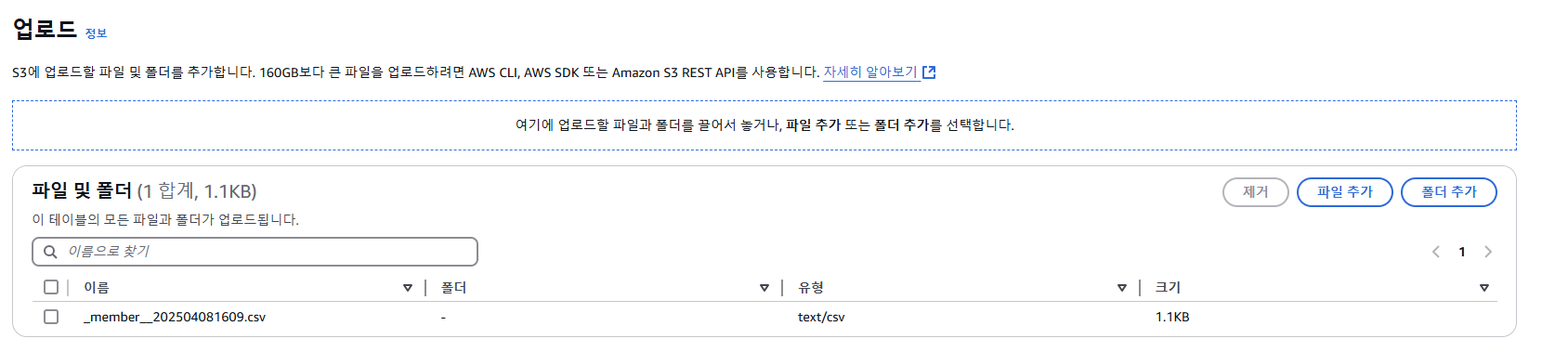
성공적으로 S3에 CSV파일 업로드가 완료되었다.
다음 포스팅에서는 업로드된 CSV파일을 AWS Athena에서 SQL로 조회해보는 과정을 담아보도록 하겠다.
